
The term Big Data was first coined in 2005 by Roger Mougalas to refer to massive amounts of online data that were nearly impossible to process. Since then, the idea of Big Data has spawned a bevy of new industries, laws, and careers with the express interest of meeting the challenges of Big Data head-on.
The term itself is often used to denote the challenges businesses face in accurately ingesting (integrations), governing (GDPR, CCPA), and analyzing the massive amounts of user data they have stored. Yet, as with all online challenges, the conversation has in the last few years moved from “Can we wrangle Big Data?” to “What’s the most efficient data storage practice to analyze my data?”
Enter the concepts of Data Lakes and Data Warehouses. Depending on your familiarity, the critical thing to keep in mind is the two concepts on how to store and process data are similar but have some significant differences.
What is a Data Lake?
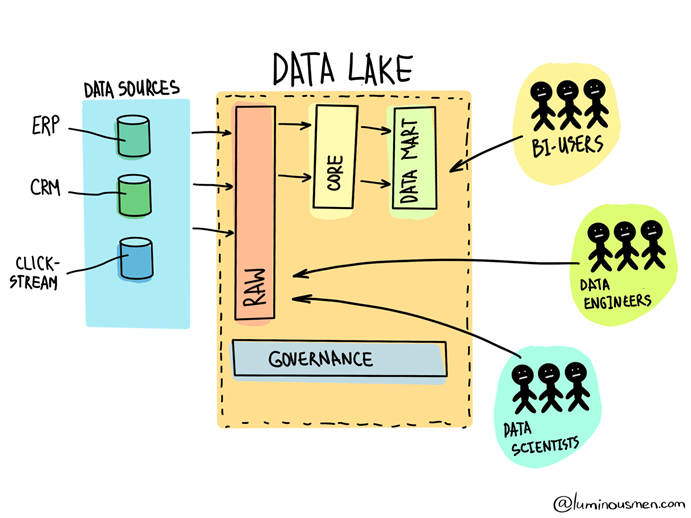
At a high level, a Data Lake is a data repository that intakes data from several sources designed to be adaptable, fluid, and easy to change depending on the question you need to answer.
With a Data Lake, all data is stored regardless of source and structure and is only segmented when ready to be analyzed. This is often referred to as “Schema on Read.”
In a Data Lake:
- Data is often imported from a multitude of sources.
- All data is retained in case it might be used eventually.
- Data is stored in a singular, fluid architecture and can be called upon when needed.
- Data is often stored as Raw Data or as a mix of unstructured and structured formats.
What are the Pros of a Data Lake?
- Multiple Layers of Access: Since data isn’t structured until it’s called, data can be accessed by reporting tools and allow unfettered access to the raw data for deeper analysis by Data Scientists and Engineers simultaneously.
- Complex Analysis: Because Data is stored in a Raw Format by default, complex analysis can be made against large stores of unstructured data often favored by algorithms designed for pattern recognition and deep analysis.
- Multiple formats at High Volume: Data lakes intake data from multiple sources in any format and volume, providing raw access to data preferred by AI and machine learning initiatives.
- Need for Speed: Since data within a data lake isn’t segmented until requested for analysis by a user, data can be accessed and written more quickly.
- Storage Costs: A data lake is significantly more affordable when it comes to storage costs.
- Accessibility and Longevity of Data: Since no data is removed when stored within a data lake, it can be accessed by more users and has a longer shelf-life for analysis.
What are the Cons of a Data Lake?
- Designed for the Cloud: Data Lakes are designed to be stored in the cloud, making it significantly more challenging to deploy on-premises when required.
- Higher Learning Curve: Because data is stored raw, maintaining a data lake typically requires the help of Data Scientists and specialized tools to translate and process the data for business needs.
- Complex Data Retrieval: Data retrieval with a data lake is more complex than using a data warehouse.
- Organization and Governance: Due to intaking massive amounts of raw data from multiple sources, data lakes require strict governance and organization standards from a business to avoid creating unusable or non-compliant data.
What is a Data Warehouse?
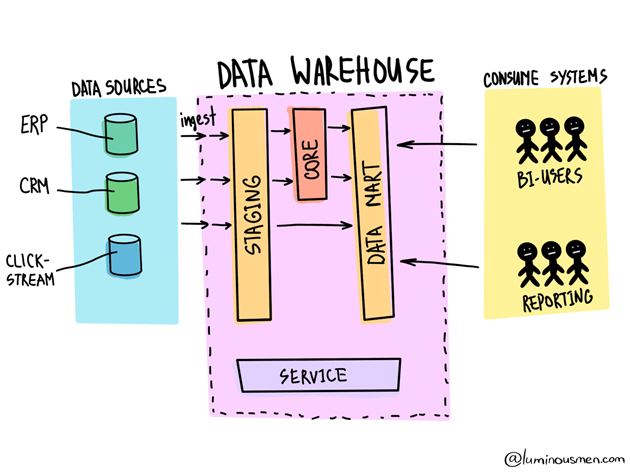
If a Data Lake is the adaptable, no-rules raw data store, then a Data Warehouse is its rigid, highly organized Type-A sibling.
At a high level, a Data Warehouse is a highly structured, subject-oriented (re: designed to answer a particular set of questions) data repository that intakes structured data from different sources with consistent data. A Data Warehouse is designed to be data-specific (inventory, sales data, etc.) structured explicitly for reporting and analysis surrounding a particular subject matter.
Only relevant structured data is stored, extracted from a data source, and immediately processed and structured when stored with a data warehouse. This is often referred to as “Schema on Write.”
In a Data Warehouse:
- Data is highly structured, rigid, and transformed for analysis upon storage.
- Data typically is paired with a year, month, day, or timestamp.
- Data is commonly single-topic, such as inventory or financial data. As a result, irrelevant data for that topic is often removed and made unavailable for analysis.
- Data warehouses combine data sets from multiple sources as long as the data structure is consistent.
What are the Pros of a Data Warehouse?
- Well-Established Data Storage Process: Data Warehouses are a mature and established industry providing a multitude of tools, experts, and practices for using Data Warehouses effectively.
- Easy and Efficient to Use: Data warehouses always use a set data structure, making it more efficient when combing through data and creating reporting from it due to its standardization and low variance in formats.
- Location Agnostic: Data warehouses can be stored in the cloud or on-premises.
- Easily Create Subsets: Data warehouses can utilize data marts (subsets of a Data Warehouse) to provide increased access to specific data sets surrounding specific lines of business (products, departments, topics) for easier reporting.
What are the Cons of a Data Warehouse?
- High Storage Costs: Compared to a data lake, storage for large volumes of data in a data warehouse is significantly more expensive.
- Complex Integration: Data warehouses require strict structure from their data sources, creating hurdles (time, money, errors) when ingesting and processing historical data or mixed data from an unstructured data source.
- Limited Data Based on Current Needs: Since data warehouses are topic-specific and have a high storage cost, businesses often have to decide what data they’ll need from a cost versus an actual data perspective.
- Struggles with advances in Big Data: A data warehouse can struggle with massive data analysis, creating significant limits for data scientists when trying to answer complex questions the data warehouse wasn’t designed to answer.









